OWOW
現在、コンテンツはありません
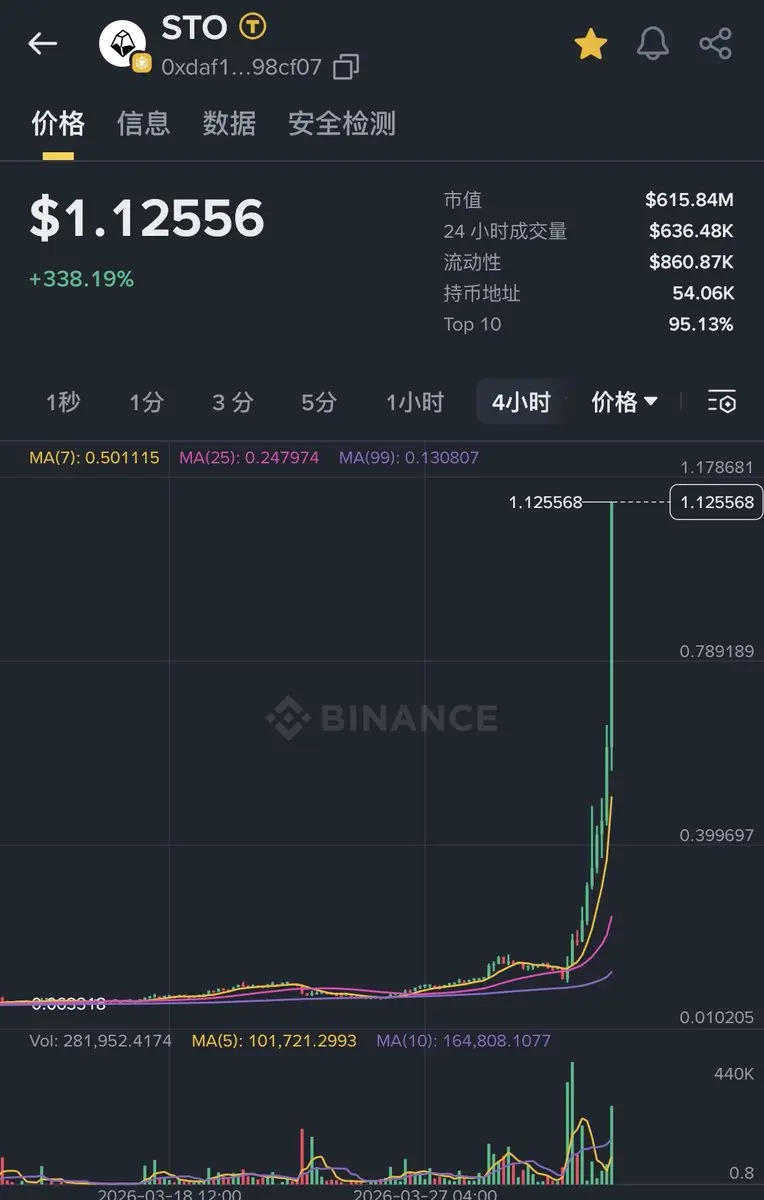
OW 毎日大金狗 4/1
ライブ配信ルーム:
原文表示ライブ配信ルーム:
- 報酬
- いいね
- コメント
- リポスト
- 共有
OW每日大金狗 3/30
ライブ配信:
原文表示ライブ配信:
- 報酬
- いいね
- コメント
- リポスト
- 共有
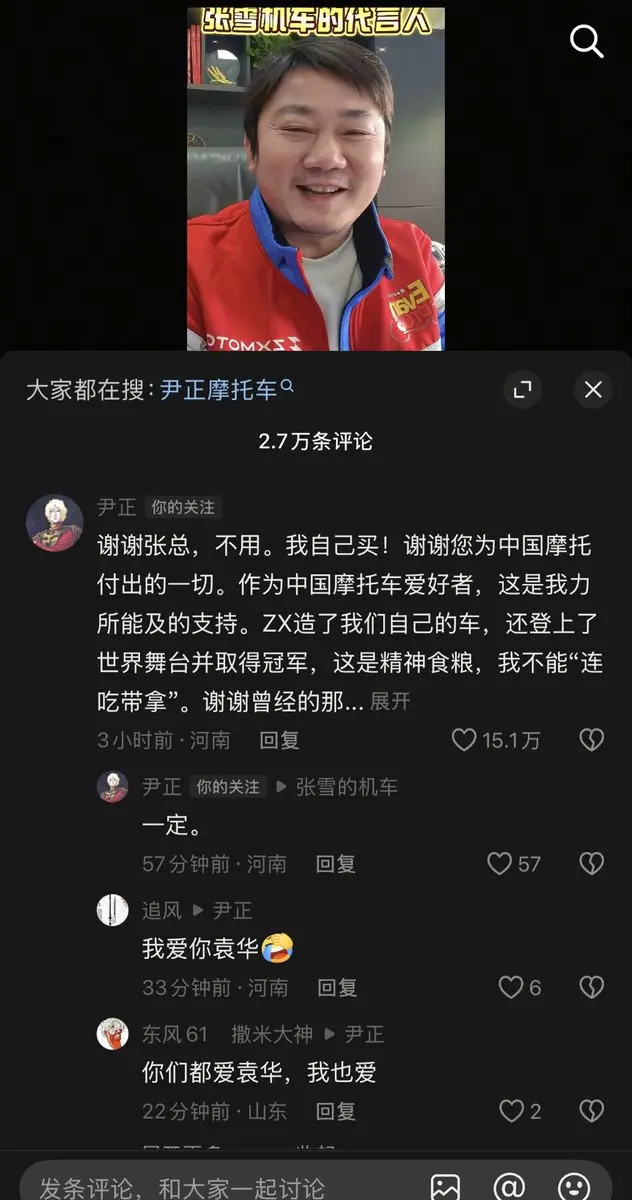
あのかつて壊れたバイクに乗って絶えずエンストし倒れながらも夢を諦めなかった田舎の若者は、最終的に自分のバイクを世界レベルのレースのチャンピオンの座に導いた!
彼は夢を追い続け、そのすべては始まりに過ぎない
#張雪機車
原文表示彼は夢を追い続け、そのすべては始まりに過ぎない
#張雪機車

- 報酬
- 1
- コメント
- リポスト
- 共有
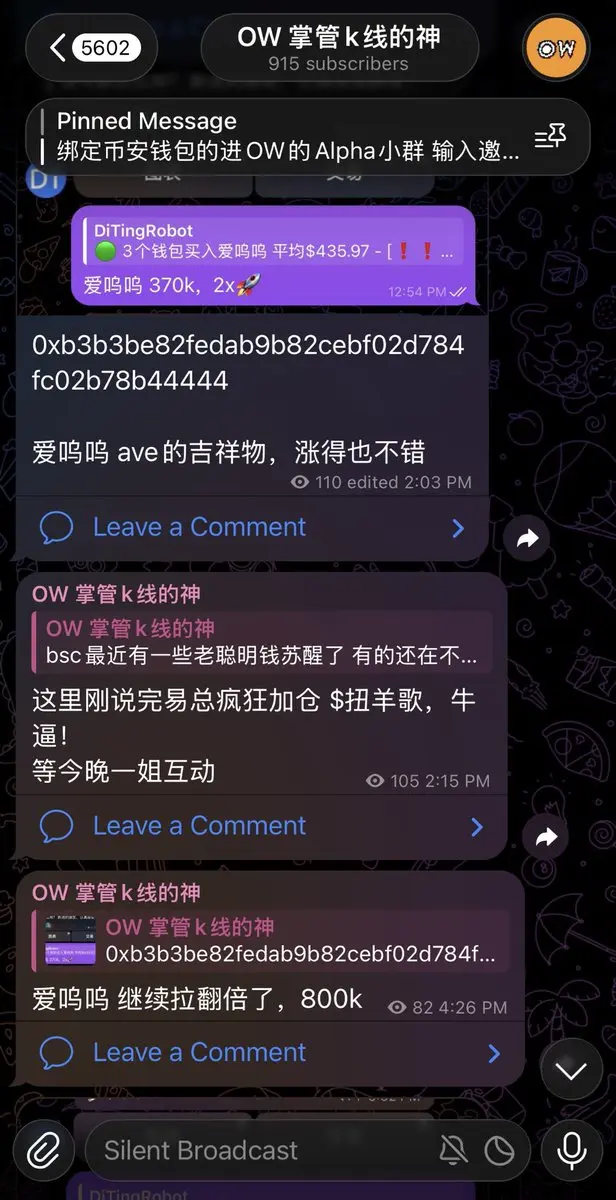
群友:
扭羊歌得亏小易在,昨天那么多热点meme愣是挺住了
OW观点:
是有原因不过也不全是
更重要是现在流动性好,非二圣、好角度都能V,多个秒200k,印证这一点
大户不会做慈善,只是想赚更多
大户一般大手笔的时候,最看重的是时机
昨天,先有易总搞建设扭羊歌,后有ave吉祥物,然后james张雪机车,这不是巧合,庄和大户都在集体出动,bsc meme时机可能到了
另哥D,猫哥最近开始活跃,但以他们为中心好的标的还没出现,这两天可以注意下
群友:
明白了,这个标的没筹码,就趁着流动性好自己去开个盘子吸血,是这个意思吧
OW:
并不是吸血,是找到好的标的,自己带头猛干
如果易总这波操作真的起了示范效果,被二圣或相关的看到和认可,我相信其他车头也会选好标的来一起走bsc建设的路,再信一次build,而不是纯日结😂
之前的社区build有2种类型
1种以sora为代表的纯技术流支持
2种以格林为代表的纯嘴巴流支持
好像走不通
现在来了第三种,纯砸钱流支持
看看怎么个事😅
我希望bsc的社区建设型meme能成!
多做出几个100m,500m,甚至1b的meme,重现bsc meme当年的荣光
@heyi @cz_ @fourdotmemezh
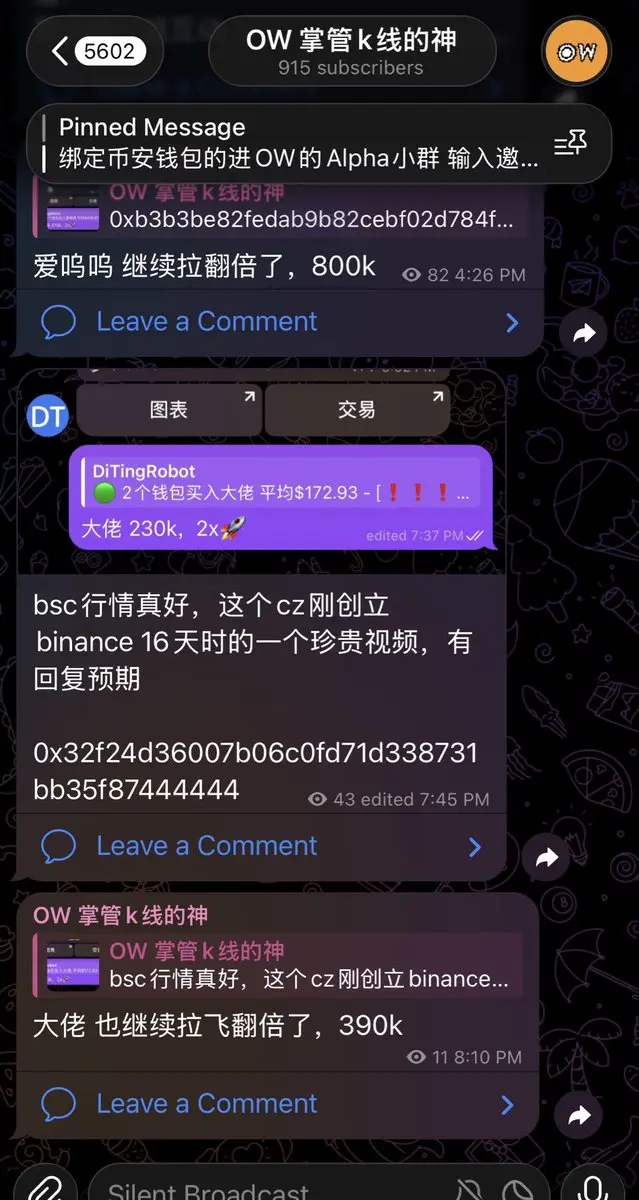
扭羊歌得亏小易在,昨天那么多热点meme愣是挺住了
OW观点:
是有原因不过也不全是
更重要是现在流动性好,非二圣、好角度都能V,多个秒200k,印证这一点
大户不会做慈善,只是想赚更多
大户一般大手笔的时候,最看重的是时机
昨天,先有易总搞建设扭羊歌,后有ave吉祥物,然后james张雪机车,这不是巧合,庄和大户都在集体出动,bsc meme时机可能到了
另哥D,猫哥最近开始活跃,但以他们为中心好的标的还没出现,这两天可以注意下
群友:
明白了,这个标的没筹码,就趁着流动性好自己去开个盘子吸血,是这个意思吧
OW:
并不是吸血,是找到好的标的,自己带头猛干
如果易总这波操作真的起了示范效果,被二圣或相关的看到和认可,我相信其他车头也会选好标的来一起走bsc建设的路,再信一次build,而不是纯日结😂
之前的社区build有2种类型
1种以sora为代表的纯技术流支持
2种以格林为代表的纯嘴巴流支持
好像走不通
现在来了第三种,纯砸钱流支持
看看怎么个事😅
我希望bsc的社区建设型meme能成!
多做出几个100m,500m,甚至1b的meme,重现bsc meme当年的荣光
@heyi @cz_ @fourdotmemezh
- 報酬
- 1
- コメント
- リポスト
- 共有
#meme 最近のBSC市場は好調だ
二聖ではなくても高値を引き出せる、二聖は迷わず突き進め
グループの信号をしっかり見て、チャンネルも注視して、安定して利益を確保
チャンネル登録:
ダイレクトメッセージで小さなグループに参加:
原文表示二聖ではなくても高値を引き出せる、二聖は迷わず突き進め
グループの信号をしっかり見て、チャンネルも注視して、安定して利益を確保
チャンネル登録:
ダイレクトメッセージで小さなグループに参加:
- 報酬
- 2
- コメント
- リポスト
- 共有
3/18 OW毎日大金狗
xライブ配信:
原文表示xライブ配信:
- 報酬
- いいね
- コメント
- リポスト
- 共有
最近数日間、レーサーのジョージ・ラッセルを追いかけている。顔を近づけて毎日追いかけている。この感覚は本当に不思議だ。彼は本当にハンサムで、彼女を連れている。彼の創造的なグッズをたくさん見た。中国人は本当に才能がある。
幼少期の名声からプレッシャーへの対抗まで
成功への渇望について言えば、これまで以上に良いパフォーマンスを出したいと強く願っている!
すべてを同時に手に入れることはできない。チャンスをくれ。数レース後にまた見よう。
原文表示幼少期の名声からプレッシャーへの対抗まで
成功への渇望について言えば、これまで以上に良いパフォーマンスを出したいと強く願っている!
すべてを同時に手に入れることはできない。チャンスをくれ。数レース後にまた見よう。


- 報酬
- いいね
- コメント
- リポスト
- 共有
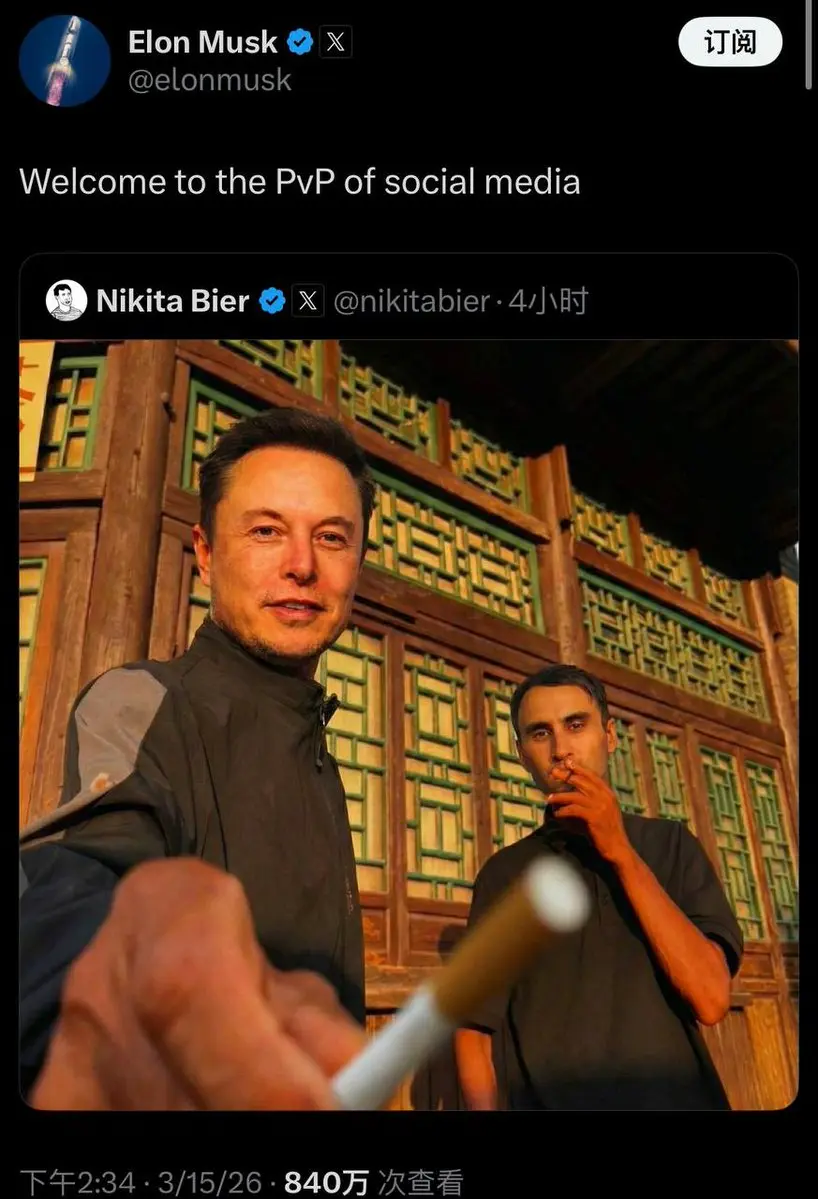
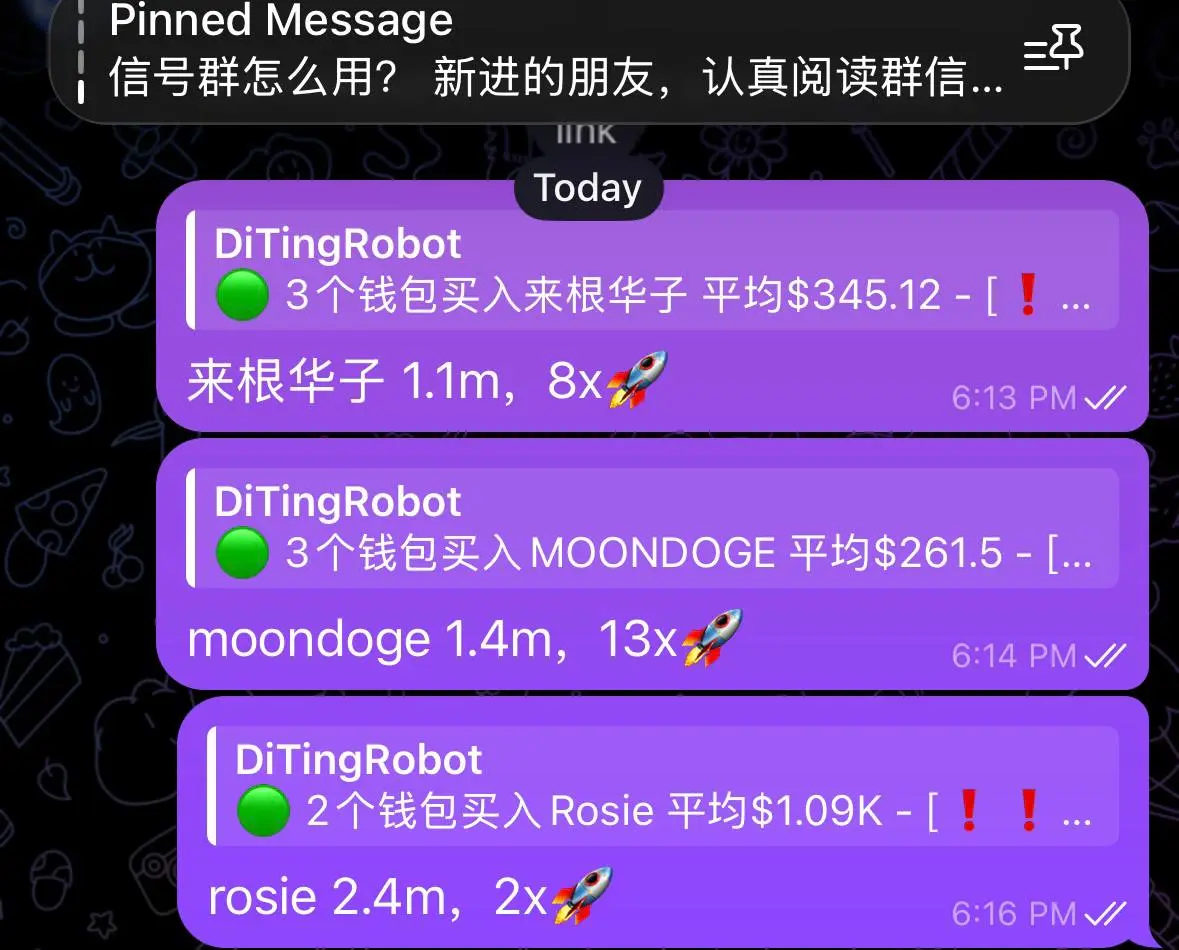
華子を一服して、チェーン上の波動を引き起こす
トッププレイヤーのPVPの世界
稼げるCAはもちろん重要だけど、面白いネタもすべてオンチェーンに載せられる
週末の相場はいつもこんなに楽しく賑やかだ
欲張らずに、堅実に稼ごう
原文表示トッププレイヤーのPVPの世界
稼げるCAはもちろん重要だけど、面白いネタもすべてオンチェーンに載せられる
週末の相場はいつもこんなに楽しく賑やかだ
欲張らずに、堅実に稼ごう
- 報酬
- いいね
- コメント
- リポスト
- 共有