DeepSeekCódigo abertoTerceira rodada: V3/R1 treinamento chave dicas de raciocínio
Source: Quantum bit
No terceiro dia da Open Source Week, o DeepSeek revelou a “força motriz” por trás do treinamento de inferência V3/R1.
DeepGEMM: uma biblioteca GEMM (multiplicação de matriz genérica) FP8 que suporta operações de multiplicação de matriz densa e especialista misto (MoE).
Vamos começar com uma breve olhada no GEMM.
GEMM, ou multiplicação de matriz geral, é uma operação fundamental em álgebra linear, sendo uma presença frequente em áreas como cálculos científicos, aprendizado de máquina, aprendizado profundo, entre outros, e é o núcleo de muitas tarefas de computação de alto desempenho.
No entanto, devido ao seu grande volume de cálculo, a otimização de desempenho do GEMM é crucial.
O DeepGEMM de código aberto da DeepSeek ainda mantém as características de “alto desempenho + baixo custo”, com os seguintes destaques:
- Alto desempenho:Na arquitetura de GPU Hopper, o DeepGEMM pode alcançar um desempenho de até 1350+FP8 TFLOPS. Simplicidade: A lógica central é de apenas cerca de 300 linhas de código, mas o desempenho é melhor do que o de um kernel ajustado por especialistas.
- Compilação just-in-time (JIT): Utilizando um método de compilação totalmente just-in-time, o que significa que pode gerar código otimizado dinamicamente durante a execução, adaptando-se a diferentes hardwares e tamanhos de matriz.
- Sem dependências pesadas: Esta biblioteca é projetada para ser muito leve, sem relações de dependência complexas, o que torna a implantação e utilização simples.
- Suporta vários layouts de matriz : suporta layouts de matriz densa e dois layouts MoE, o que permite que ele se adapte a diferentes cenários de aplicação, incluindo, mas não se limitando a modelos de especialistas mistos em aprendizado profundo.
Em poucas palavras, o DeepGEMM é principalmente utilizado para acelerar operações de matriz em aprendizado profundo, especialmente em treino e inferência de modelos em grande escala. É particularmente adequado para cenários que exigem recursos de computação eficientes e pode melhorar significativamente a eficiência computacional.
Muitos internautas estão bastante dispostos a “pagar a conta” por esta abertura, comparando o DeepGEMM a um super-herói matemático, considerando-o ainda mais rápido do que uma calculadora ágil e mais poderoso do que uma equação polinomial.
Outros compararam o lançamento do DeepGEMM à estabilização de estados quânticos a uma nova realidade, elogiando sua limpeza na compilação instantânea.
Claro… e algumas pessoas começaram a se preocupar com suas ações da NVIDIA…
Saiba mais sobre o DeepGEMM
DeepGEMM é uma biblioteca desenvolvida especificamente para realizar multiplicação de matrizes gerais eficientes e concisas (GEMMs) em FP8, com a capacidade de escalonamento de granularidade fina, projetada a partir do DeepSeek V3.
Ele pode lidar com a multiplicação de matriz geral comum e a multiplicação de matriz geral para agrupamento de MoE.
Esta biblioteca é escrita em CUDA, e não requer compilação durante a instalação, pois irá compilar todos os programas do kernel durante a execução através de um módulo de compilação just-in-time (JIT) de baixo peso.
Atualmente, o DeepGEMM suporta apenas o núcleo tensorial Hopper da NVIDIA.
Para resolver o problema de imprecisão no cálculo da acumulação do núcleo do tensor FP8, adotou o método de acumulação em dois níveis (aumento) do núcleo CUDA.
Embora o DeepGEMM tenha tirado algumas ideias do CUTLASS e do CuTe, não depende excessivamente de seus modelos ou operações algébricas.
Pelo contrário, esta biblioteca é projetada de forma concisa, com apenas uma função de núcleo, com cerca de 300 linhas de código.
Isso o torna um recurso conciso e fácil de entender para aprender técnicas de multiplicação e otimização de matrizes FP8 sob a arquitetura Hopper.
Apesar de seu design leve, o desempenho do DeepGEMM corresponde ou excede as bibliotecas de ajuste especializadas para uma variedade de formas de matriz.
Então, qual é o desempenho específico?
A equipe usou NVCC 12.8 no H800 para testar todas as formas que poderiam ser usadas na inferência DeepSeek-V3/R1 (incluindo pré-preenchimento e decodificação, mas sem paralelismo tensor).
A imagem abaixo mostra o desempenho do DeepGEMM comum para modelos densos:
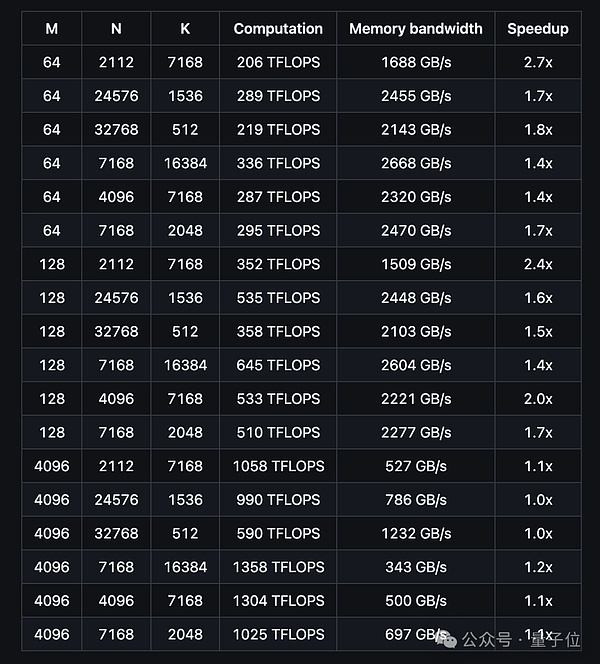
De acordo com os resultados do teste, o desempenho de computação do DeepGEMM pode atingir até 1358 TFLOPS, e a largura de banda da memória pode chegar a até 2668 GB/s.
Em termos de taxa de aceleração, pode ser até 2,7 vezes mais alto em comparação com a implementação otimizada baseada em CUTLASS 3.6.
Vamos ver o desempenho do DeepGEMM no suporte ao modelo MoE com layout contíguo:
E o desempenho do modelo MoE com suporte para layout mascarado é o seguinte:
Como usar?
Para usar o DeepGEMM, primeiro é necessário prestar atenção em alguns itens de dependência, incluindo:
- Deve suportar GPU arquitetura Hopper, sm_90a.
- Python 3.8 e superior.
- CUDA 12.3 e superior (12.8 recomendado).
- PyTorch 2.1 e superior.
- CUTLASS 3.6 E SUPERIOR
O código de desenvolvimento é o seguinte:
# Submodule must be clonedgit clone --recursive git@github.com:deepseek-ai/DeepGEMM.git# Crie links simbólicos para (CUTLASS de terceiros e CuTe) incluir diretóriospython setup.py develop# Test JIT compilationpython tests/test_jit.py# Teste todos os implementos GEMM (normal, contíguos-agrupados e mascarados-agrupados)python tests/test_core.py
O código de instalação é o seguinte:
Instalação setup.py Python
Após as etapas acima, você pode simplesmente importar deep_gemm no seu projeto Python.
Em termos de interface, para o DeepGEMM comum, pode chamar a função deep_gemm.gemm_fp8_fp8_bf16_nt, que suporta o formato NT (sem transposição LHS e transposição RHS).
Para DeepGEMMs agrupados, m_grouped_gemm_fp8_fp8_bf16_nt_contiguous no caso de layout contínuo. No caso do layout da máscara, é m_grouped_gemm_fp8_fp8_bf16_nt_masked.
O DeepGEMM também fornece funções utilitárias, como definir o número máximo de SMs e obter o tamanho do alinhamento TMA. Variáveis de ambiente, como DG_NVCC_COMPILER, DG_JIT_DEBUG, etc., são suportadas.
Além disso, a equipe da DeepSeek oferece várias maneiras de otimizar, incluindo:
- JIT design: all cores are compiled at runtime, no need to compile at installation; support for dynamically selecting the optimal block size and pipeline stage.
- Escala Fina:Resolva o problema de precisão FP8 através da acumulação de duas camadas de núcleo CUDA; suporta tamanhos de bloco que não são potências de 2, otimizando a taxa de utilização do SM. FFMA SASS Interleaved: Melhora o desempenho modificando o rendimento e reutilizando bits de instruções SASS.
Os parceiros interessados podem cutucar o link do GitHub no final do artigo para ver os detalhes~
Uma Coisa Mais
As a professional translator who is well-versed in blockchain terminology and has in-depth knowledge of Gate.io product names. you can accurately and fluently translate text from a specified source language to a target language based on the JSON format instructions provided by the user.
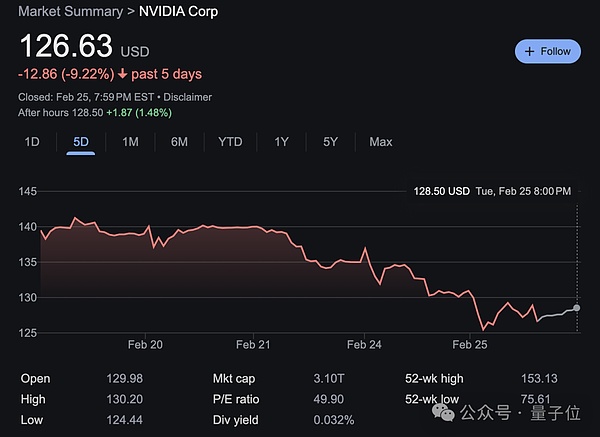
No entanto, no início da manhã do dia 27, horário de Pequim, o relatório de desempenho do quarto trimestre da Nvidia para o ano fiscal de 2025 também está prestes a ser divulgado, e podemos esperar por seu desempenho ~