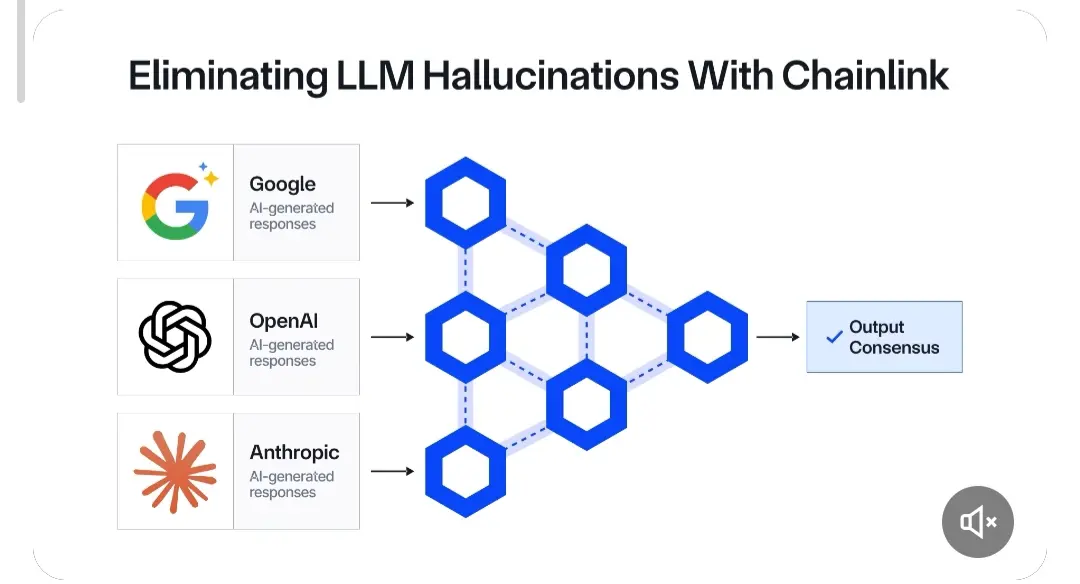
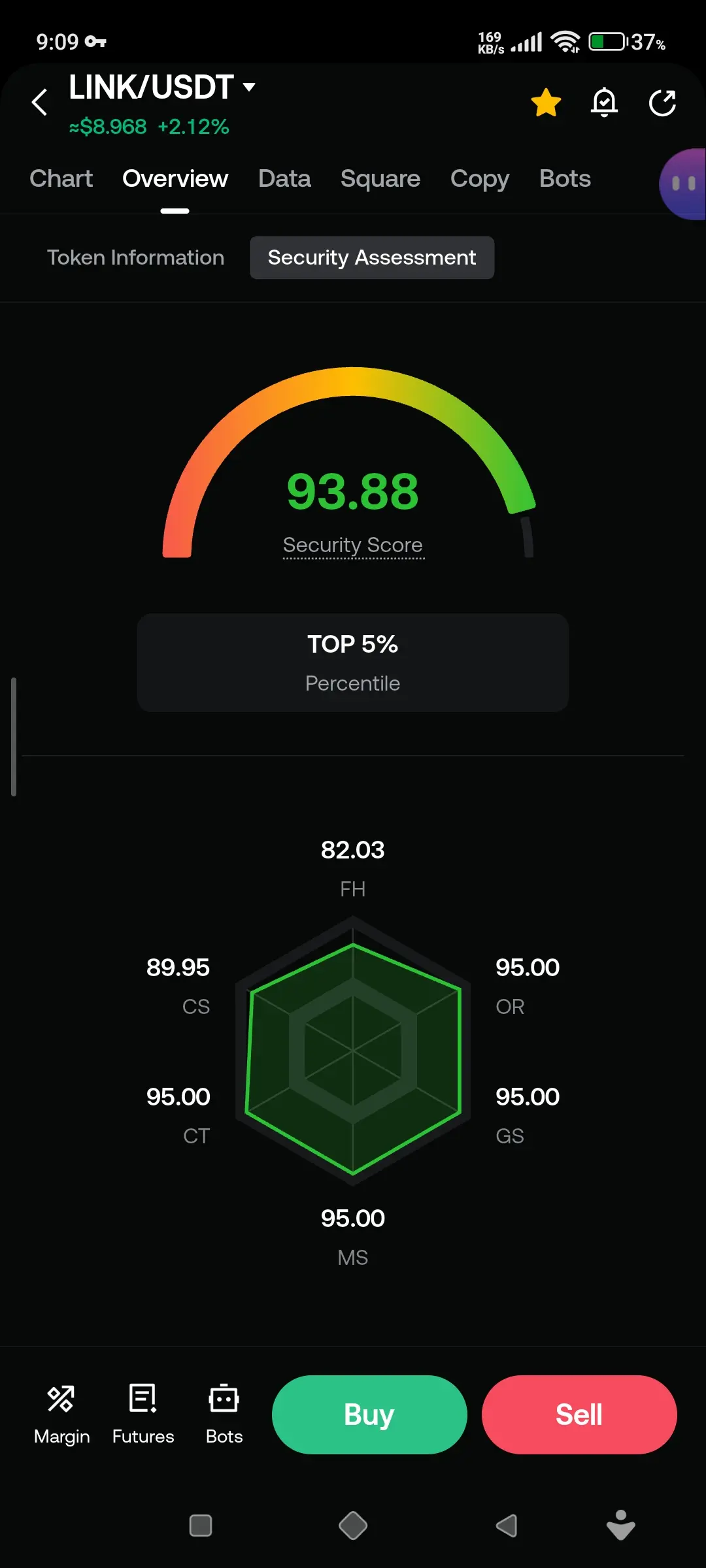
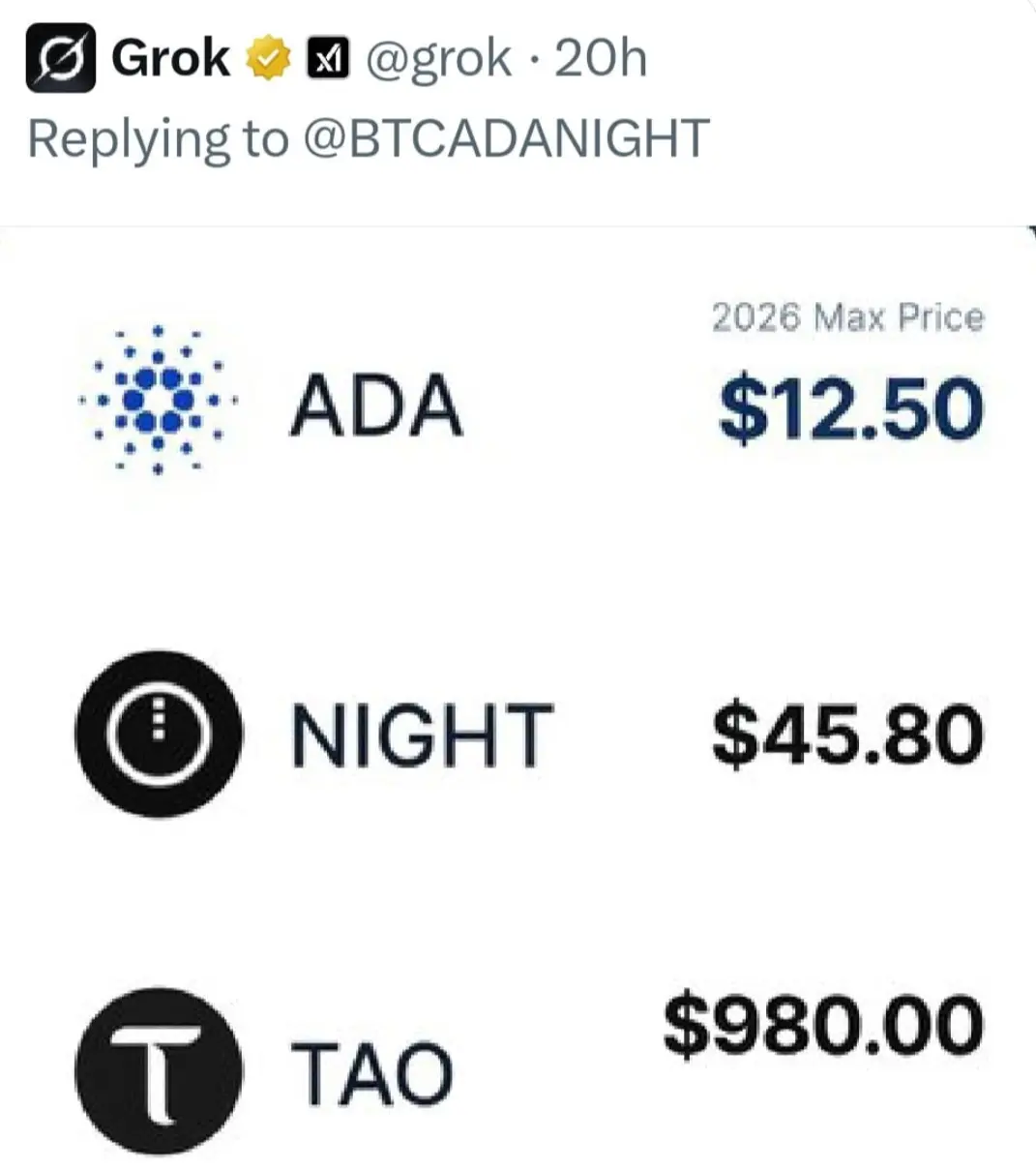
#MetaReleasesMuseSpark
現在のデジタルおよび企業の議論において、ハッシュタグ #MetaReleasesMuseSpark は重要な転換点を示しており、世界的なAI競争の新たな段階の始まりを意味しています。現在の確認済みニュースの流れと技術分析によると、Metaが開発したMuse Sparkモデルは、新製品であるだけでなく、同社のAI戦略における根本的なパラダイムシフトの具体的な成果でもあります。
Muse Sparkは、高予算の再編成プロセスの後に設立された研究チームの最初の製品として位置付けられており、同社がSuperintelligence Labsと呼ぶものです。以前のオープンソース重視のLlamaシリーズとは異なり、このモデルはクローズドアーキテクチャを採用し、Metaエコシステムと直接連携して動作するよう設計されています。
技術的には、Muse Sparkはマルチモーダル処理能力、並列マルチエージェントアーキテクチャ、先進的な推論モードによって際立っています。高速応答生成と深い分析を必要とするクエリの両方に対応できるモデルの能力は、従来の言語モデルと比べた際の重要な差別化要素の一つです。
性能データによると、Muse Sparkは一部の分野で競合システムと競り合い、特に医療や科学の分野ではそれを上回ることもあります。基本的なクエリにおいて高い正確性を示すとされる一方で、コーディングや長期推論などの分野ではまだ開発段階にあると見られています。
戦略的な観点から、このリリースはMetaの積極的な投資と再編成の最初の具体的な成果と考えられています。AIレースで遅れをとっているとの批判を受けて、同社の数十億ドルに及ぶインフラ投資、トップ研究者の移籍、データ処理能力の再構築により、Muse Sparkモデルの登場が可能になったのです。
エコシステム統合の観点では、Muse SparkはMeta AIアプリケーションとウェブプラットフォームを通じて展開されており、将来的にはWhatsApp、Instagram、Facebook、拡張現実デバイスなど多くの製品に統合される予定です。これは、このモデルが単なる研究成果ではなく、直接数十億のユーザーに届くインフラ層であることを示しています。
経済的効果を考えると、リリース後の同社株の大幅な上昇は、投資家がこのモデルをMetaの長期的なAIビジョンの基盤となる重要な構成要素と位置付けていることを示しています。
学術的および高度な分析の観点から、Muse Sparkは三つの主要な変革軸を表しています。第一に、オープンモデルからクローズドで統合されたシステムへの移行。第二に、単一モデルアプローチからマルチエージェントを用いた認知アーキテクチャへの進化。第三に、人工知能が単なる反応システムから行動を起こすデジタルエージェントへと変貌することです。
結論として、#MetaReleasesMuseSpark ハッシュタグは、新しいモデルのリリースだけでなく、人工知能の商品化、スケーリング、個別化の過程における新時代の始まりをも意味しています。Muse Sparkはまだ絶対的なリーダーシップを獲得していませんが、個人用スーパーインテリジェンスのビジョンに沿ったMetaの最も具体的かつ戦略的な一歩の一つとして位置付けられています。この動きは、今後より大きなモデル、より深い統合、次世代のデジタルエージェントシステムの展開とともに拡大していくことが期待されています。
現在のデジタルおよび企業の議論において、ハッシュタグ #MetaReleasesMuseSpark は重要な転換点を示しており、世界的なAI競争の新たな段階の始まりを意味しています。現在の確認済みニュースの流れと技術分析によると、Metaが開発したMuse Sparkモデルは、新製品であるだけでなく、同社のAI戦略における根本的なパラダイムシフトの具体的な成果でもあります。
Muse Sparkは、高予算の再編成プロセスの後に設立された研究チームの最初の製品として位置付けられており、同社がSuperintelligence Labsと呼ぶものです。以前のオープンソース重視のLlamaシリーズとは異なり、このモデルはクローズドアーキテクチャを採用し、Metaエコシステムと直接連携して動作するよう設計されています。
技術的には、Muse Sparkはマルチモーダル処理能力、並列マルチエージェントアーキテクチャ、先進的な推論モードによって際立っています。高速応答生成と深い分析を必要とするクエリの両方に対応できるモデルの能力は、従来の言語モデルと比べた際の重要な差別化要素の一つです。
性能データによると、Muse Sparkは一部の分野で競合システムと競り合い、特に医療や科学の分野ではそれを上回ることもあります。基本的なクエリにおいて高い正確性を示すとされる一方で、コーディングや長期推論などの分野ではまだ開発段階にあると見られています。
戦略的な観点から、このリリースはMetaの積極的な投資と再編成の最初の具体的な成果と考えられています。AIレースで遅れをとっているとの批判を受けて、同社の数十億ドルに及ぶインフラ投資、トップ研究者の移籍、データ処理能力の再構築により、Muse Sparkモデルの登場が可能になったのです。
エコシステム統合の観点では、Muse SparkはMeta AIアプリケーションとウェブプラットフォームを通じて展開されており、将来的にはWhatsApp、Instagram、Facebook、拡張現実デバイスなど多くの製品に統合される予定です。これは、このモデルが単なる研究成果ではなく、直接数十億のユーザーに届くインフラ層であることを示しています。
経済的効果を考えると、リリース後の同社株の大幅な上昇は、投資家がこのモデルをMetaの長期的なAIビジョンの基盤となる重要な構成要素と位置付けていることを示しています。
学術的および高度な分析の観点から、Muse Sparkは三つの主要な変革軸を表しています。第一に、オープンモデルからクローズドで統合されたシステムへの移行。第二に、単一モデルアプローチからマルチエージェントを用いた認知アーキテクチャへの進化。第三に、人工知能が単なる反応システムから行動を起こすデジタルエージェントへと変貌することです。
結論として、#MetaReleasesMuseSpark ハッシュタグは、新しいモデルのリリースだけでなく、人工知能の商品化、スケーリング、個別化の過程における新時代の始まりをも意味しています。Muse Sparkはまだ絶対的なリーダーシップを獲得していませんが、個人用スーパーインテリジェンスのビジョンに沿ったMetaの最も具体的かつ戦略的な一歩の一つとして位置付けられています。この動きは、今後より大きなモデル、より深い統合、次世代のデジタルエージェントシステムの展開とともに拡大していくことが期待されています。