#### 概要* Microsoftは、AI研究の品質を高めるためにGPTとClaudeを組み合わせる2つの異なるモードをリリースした。* Critiqueはモデル同士の協働を促すのに対し、Councilは並列で作業させ、3人目の判定役が相違点を見つける。* この2モデルのワークフローにより、幻覚、弱い引用、そして単一モデルのAI研究に関連するその他の問題が解消される。生成AIのディープリサーチは、今年のテック界で最も熱い(激しい)競争の1つとなっている。今年(2024年)の12月にGoogleがGemini向けのリサーチエージェントを発表し、2025年2月にはOpenAIが独自のリサーチエージェントをリリースし、xAIも追随した。Perplexityはさらに注力し、AnthropicのClaudeは、詳細で根拠付きの回答を必要とするプロフェッショナルの間で強い支持を集め、昨年4月にそのエージェントを導入した。どの会社も、部屋の中で最も賢い研究者は自社の「単一のAIモデル」だとあなたを説得しようとしてきた。Microsoftはただこう言ったのだ。「1つに絞る必要はあるのか?」同社は月曜日に、CopilotのResearcherツール向けの2つの新機能として、CritiqueとCouncilを発表した。これは、OpenAIのGPTとAnthropicのClaudeを同じ研究タスクで順番に動かすものだ。業界ベンチマークに対するMicrosoftのテストによれば、その結果はそのテストに含まれているあらゆるシステム、つまりトップAI企業のモデルを含む全てを上回るという。> M365 Copilotの新しいマルチモデル・ディープリサーチシステム「Critique」をご紹介します。> > 複数のモデルを一緒に使って、最適な回答とレポートを生成できます。pic.twitter.com/m4RlQmCKzs> > — Satya Nadella (@satyanadella) March 30, 2026「Critiqueは、複雑な研究タスク向けに設計された新しいマルチモデル・ディープリサーチシステムです。生成と評価を分離し、AnthropicやOpenAIを含むFrontierラボの複数のモデルの組み合わせを活用します」とMicrosoftは説明する。「1つのモデルが生成フェーズを主導し、タスクを計画し、検索を反復して、初期ドラフトを作成します。一方、2つ目のモデルは、最終レポートが作成される前に、事実の正確性、引用の質、そして回答が実際に求められた内容に取り組んでいるかどうかを、専門家のレビューアとして重視し、レビューと洗練に集中します。」Critiqueが解決しようとしている基本的な問題はこれだ。Critiqueの設計が直すべきこと:今日のあらゆるAIリサーチツールは、同じやり方で動いている。あなたが質問をすると、1つのモデルが検索を計画し、情報源を洗い、レポートを書いて、あなたに返す。その単一モデルが、何のチェックも受けずにすべてを行っている。その結果、幻覚が紛れ込んだり、引用に誤りが出たり、捏造や不正確な主張が入ったりすることがある。<span data-mce-type="bookmark" style="display:inline-block;width:0px;overflow:hidden;line-height:0" class="mce_SELRES_start"></span>Critiqueは、そのワークフローを2つに分けて壊す。GPTが最初のフェーズを担当する。研究を計画し、情報源を取り込み、初期ドラフトを書く。次にClaudeが厳格な編集者として入り、レポートを事実の正確性、引用の品質、そして回答が依頼された内容を実際に扱っているかどうかの観点でレビューする。そのレビューの後になって初めて、最終レポートがユーザーに届く。Microsoftによれば、役割は最終的に逆方向でも動かせるという。つまり、Claudeが下書きを作りGPTが批評する形だが、現時点ではGPTが先に進む。DRACOベンチマーク(医療、法務、テクノロジーを含む10の領域にまたがり、100の複雑な研究タスクをカバーする標準化テスト)では、Critiqueを搭載したCopilotのスコアは57.4。点だった。AnthropicのClaude Opusは単独で42.7。点だった。Microsoftの統合システムは、次に良い結果との差を約14%で上回っている。最大の伸びが見られたのは、分析の幅とプレゼンテーションの質であり、事実の正確性も大きく改善された。2つ目の機能であるCouncilは、同じ問題に対して別のアプローチを取る。相手の作業を1つのモデルにレビューさせるのではなく、CouncilはGPTとClaudeを_同時に_動かし、それぞれの完全なレポートを並べて提示する。さらに、その2つを読み取る3つ目の「判定役」モデルが、両者がどこで一致したのか、どこで食い違ったのか、そしてそれぞれが相手の見落としていた独自の視点をどこで捉えたのかを説明する要約を書き出す。AIのリサーチツールを手作業で比較することは、これまでユーザー自身が行わなければならなかった。Critiqueでは、モデル同士は本質的に_協働_する。一方、Councilではモデル同士が_競争_する。ResearcherにおけるCritiqueはデフォルトの体験であるのに対し、Councilは並列モードを有効化するために、ピッカーから「Model Council」を選択する必要がある。両方の機能は現在、Copilotの最新機能向けの早期アクセスチャネルであるMicrosoftのFrontierプログラムに登録したユーザーが利用できる。Microsoft 365 Copilotのライセンス($30/user/month)が必要だが、それらにアクセスするにはユーザーがFrontierにも登録している必要がある。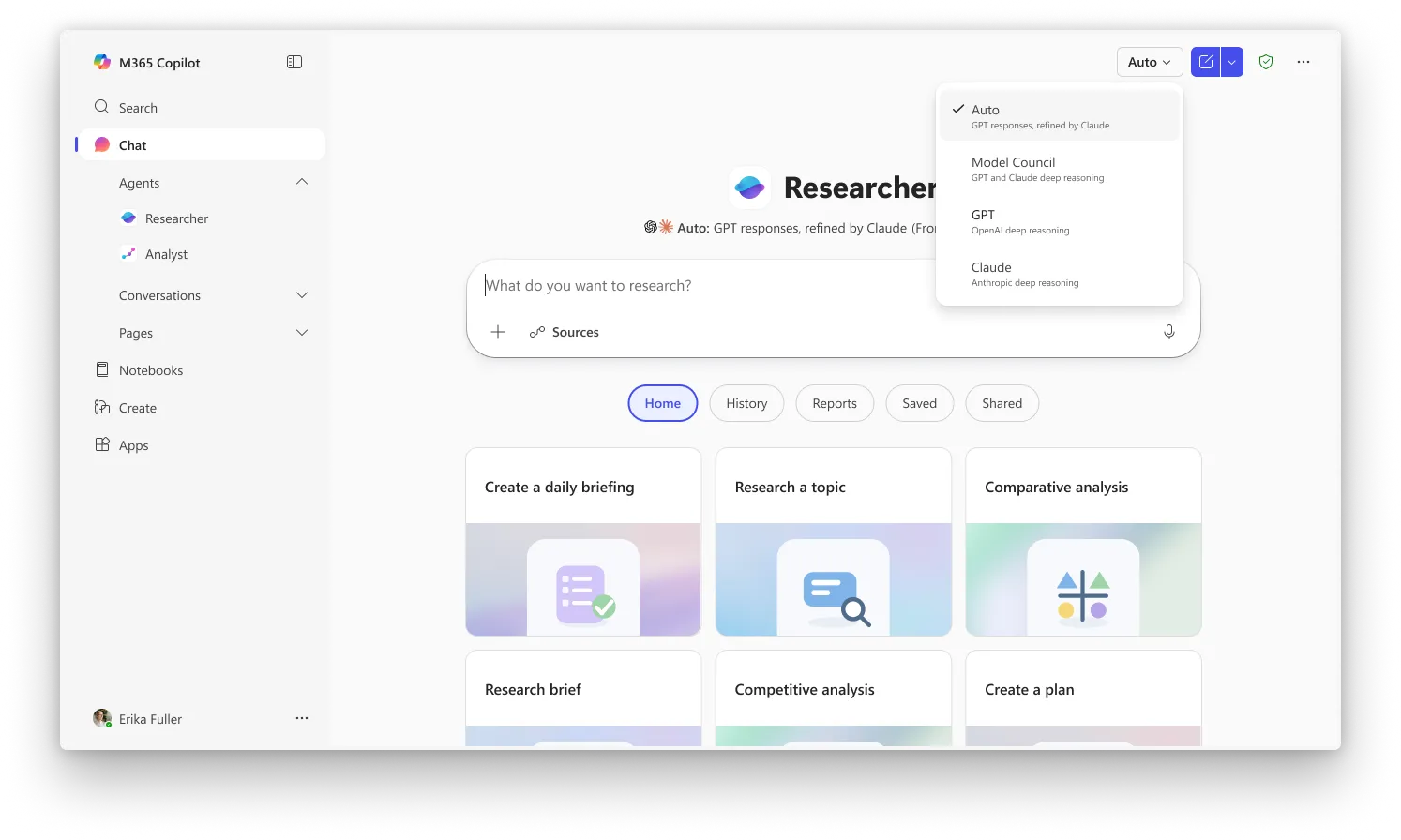Image: MicrosoftOpenAIとMicrosoftにはマルチビリオン・ドル規模のパートナーシップがあるが、Microsoftの賭けは「単一のモデルがいつまでもトップに居続けることはない」という点にある。そして、真の価値はタスクを、最も機能する組み合わせへと振り分けるオーケストレーション層にあるのだ。### デイリーデブリーフ・ニュースレター毎日、いまのトップニュース記事に加えて、オリジナルの特集、ポッドキャスト、動画などから始めましょう。Your EmailGet it!Get it!
MicrosoftがGPTとClaudeを連携させ、その結果、あらゆるAI研究ツールを凌駕しています
概要
生成AIのディープリサーチは、今年のテック界で最も熱い(激しい)競争の1つとなっている。今年(2024年)の12月にGoogleがGemini向けのリサーチエージェントを発表し、2025年2月にはOpenAIが独自のリサーチエージェントをリリースし、xAIも追随した。Perplexityはさらに注力し、AnthropicのClaudeは、詳細で根拠付きの回答を必要とするプロフェッショナルの間で強い支持を集め、昨年4月にそのエージェントを導入した。
どの会社も、部屋の中で最も賢い研究者は自社の「単一のAIモデル」だとあなたを説得しようとしてきた。Microsoftはただこう言ったのだ。「1つに絞る必要はあるのか?」
同社は月曜日に、CopilotのResearcherツール向けの2つの新機能として、CritiqueとCouncilを発表した。これは、OpenAIのGPTとAnthropicのClaudeを同じ研究タスクで順番に動かすものだ。業界ベンチマークに対するMicrosoftのテストによれば、その結果はそのテストに含まれているあらゆるシステム、つまりトップAI企業のモデルを含む全てを上回るという。
「Critiqueは、複雑な研究タスク向けに設計された新しいマルチモデル・ディープリサーチシステムです。生成と評価を分離し、AnthropicやOpenAIを含むFrontierラボの複数のモデルの組み合わせを活用します」とMicrosoftは説明する。「1つのモデルが生成フェーズを主導し、タスクを計画し、検索を反復して、初期ドラフトを作成します。一方、2つ目のモデルは、最終レポートが作成される前に、事実の正確性、引用の質、そして回答が実際に求められた内容に取り組んでいるかどうかを、専門家のレビューアとして重視し、レビューと洗練に集中します。」
Critiqueが解決しようとしている基本的な問題はこれだ。Critiqueの設計が直すべきこと:今日のあらゆるAIリサーチツールは、同じやり方で動いている。あなたが質問をすると、1つのモデルが検索を計画し、情報源を洗い、レポートを書いて、あなたに返す。その単一モデルが、何のチェックも受けずにすべてを行っている。
その結果、幻覚が紛れ込んだり、引用に誤りが出たり、捏造や不正確な主張が入ったりすることがある。
Critiqueは、そのワークフローを2つに分けて壊す。GPTが最初のフェーズを担当する。研究を計画し、情報源を取り込み、初期ドラフトを書く。次にClaudeが厳格な編集者として入り、レポートを事実の正確性、引用の品質、そして回答が依頼された内容を実際に扱っているかどうかの観点でレビューする。そのレビューの後になって初めて、最終レポートがユーザーに届く。Microsoftによれば、役割は最終的に逆方向でも動かせるという。つまり、Claudeが下書きを作りGPTが批評する形だが、現時点ではGPTが先に進む。
DRACOベンチマーク(医療、法務、テクノロジーを含む10の領域にまたがり、100の複雑な研究タスクをカバーする標準化テスト)では、Critiqueを搭載したCopilotのスコアは57.4。点だった。AnthropicのClaude Opusは単独で42.7。点だった。Microsoftの統合システムは、次に良い結果との差を約14%で上回っている。
最大の伸びが見られたのは、分析の幅とプレゼンテーションの質であり、事実の正確性も大きく改善された。
2つ目の機能であるCouncilは、同じ問題に対して別のアプローチを取る。相手の作業を1つのモデルにレビューさせるのではなく、CouncilはGPTとClaudeを_同時に_動かし、それぞれの完全なレポートを並べて提示する。さらに、その2つを読み取る3つ目の「判定役」モデルが、両者がどこで一致したのか、どこで食い違ったのか、そしてそれぞれが相手の見落としていた独自の視点をどこで捉えたのかを説明する要約を書き出す。AIのリサーチツールを手作業で比較することは、これまでユーザー自身が行わなければならなかった。
Critiqueでは、モデル同士は本質的に_協働_する。一方、Councilではモデル同士が_競争_する。
ResearcherにおけるCritiqueはデフォルトの体験であるのに対し、Councilは並列モードを有効化するために、ピッカーから「Model Council」を選択する必要がある。両方の機能は現在、Copilotの最新機能向けの早期アクセスチャネルであるMicrosoftのFrontierプログラムに登録したユーザーが利用できる。Microsoft 365 Copilotのライセンス($30/user/month)が必要だが、それらにアクセスするにはユーザーがFrontierにも登録している必要がある。
Image: Microsoft
OpenAIとMicrosoftにはマルチビリオン・ドル規模のパートナーシップがあるが、Microsoftの賭けは「単一のモデルがいつまでもトップに居続けることはない」という点にある。そして、真の価値はタスクを、最も機能する組み合わせへと振り分けるオーケストレーション層にあるのだ。
デイリーデブリーフ・ニュースレター
毎日、いまのトップニュース記事に加えて、オリジナルの特集、ポッドキャスト、動画などから始めましょう。
Your Email
Get it!
Get it!